

데이터베이스 테이블에 저장된 문자열(VARCHAR, CLOB) 데이터에서 정규표현식으로 숫자 다루는 샘플 예제입니다.
사용한 DBMS는 'PostgreSQL'
샘플 데이터는 아래와 같습니다. 문자열 안에 숫자(정수, 실수) 형태의 데이터가 포함되어 있습니다.
사용 목적: 문자열로 기록된 데이터에서 특정 항목의 값을 추출하고 싶은데 그 값이 수(NUMBER)일 때.
| Left Margin : 20cm; Right Margin: 300mm, bold=15pt, subtext : 10.5CM, largetext : 5.35cm |
수를 다룰 때 주로 사용할 정규표현식 메타문자는 다음과 같습니다.
| . (온점) | 어떤 문자든 매칭 (Matches any character) |
| ? (물음표) | 0개 ~ 1개 (Zero or One) |
| * (별표) | 0개 ~ N개 (Zero or More) |
| + (더하기) | 1개 ~ N개 (One or More) |
| \d | 모든 숫자(1자리 Digit character) |
| \D | 숫자를 제외한 모든 문자 (Non-digit character) |
| {m} | 정확히 m개 매칭 (Exactly m times) |
| {m,} | 최소 m개 매칭 (Least m times) |
| {m, n} | m개에서 n개 매칭 (Least m times but no more than n times) |
--- --- --- ---
1. REGEXP_SUBSTR()
원본 데이터에서 정규표현식으로 추출한 결과를 SELECT에 반영하는 함수입니다.
총 5개의 파라미터를 사용하지만, 너무 자세하게 다룰 필요는 없기 때문에 필수 2개만 사용하겠습니다.
REGEXP_SUBSTR(Source, Pattern) 이 일반적으로 사용하는 식입니다.
Source : 정규표현식을 적용할 데이터가 저장된 Column.
Pattern : 정규표현식
1) Right Margin 값을 가져오고 싶다.
여기서 원하는 결과는 '300'입니다. 단위까지 가져온다고 가정하면 '300mm'입니다.
값을 분명하게 가져오려면 정규표현식을 자세히 작성해야 합니다.
특수문자가 문자열에 포함되어 있다면 이를 문자라고 판단할 수 있도록 백슬래시(달러 문자 \)를 명시해야 합니다.

여기서 \d만 작성했기 때문에 1글자인 3까지만 추출되었습니다.
\d{1}은 정확히 1개의 숫자 데이터만 찾아내는 식이므로 3만 추출됩니다.
?는 0~1개의 Target과 매칭되므로 'Right Margin: 3'의 결과와 같이 나옵니다.
--- --- --- ---
만약, 뒤에 작성된 모든 수를 포함하고자 한다면 어떻게 해야 할까요.

메타문자 *은 0~N개의 Target과 매칭됩니다. 즉, 숫자(\d) 0개~N개가 연달아 있다면 계속 매칭하는 것입니다.
또한, +는 1~N개의 Target과 매칭되므로 숫자(\d) 1개~N개를 연달아 매칭합니다.
{3}은 정확히 3개가 매칭되어야 하므로 숫자(\d) 3개가 정확히 있어야 추출됩니다.
만약, 30012의 값이라면 300까지만 추출되는 것입니다.
30의 값이었다면 추출되지 않습니다.
\d{1,3}은 최소 1개에서 최대 3개의 숫자 데이터를 추출합니다.
30012라면 300, 30이라면 30, 3이라면 3으로 추출되는 형태입니다.
--- --- --- ---
혹시나, 앞의 'Right Margin:'을 제외한 '300'의 숫자만 딱 추출하고 싶다면!
후방탐색 방법을 사용해야 합니다.
'전방 탐색'과 '후방 탐색'은 추가 검색을 하시어 지식을 찾아내시면 되겠습니다.
(저도 추후 블로깅 예정입니다 ㅠㅠ)
후방탐색은 '앞의 매칭되는 표현식 이후의 매칭 결과를 추출'하는 방법으로 이해하시면 되겠습니다.
문법은 (?<=) 와 (?<!)가 있습니다.
(?<=) : 긍정형 후방탐색. 매칭되는 문자열 이후의 정규표현식 매칭 결과를 추출.
(?<!) : 부정형 후방탐색. 매칭되지 않는 문자열 이후의 정규표현식 매칭 결과를 추출.
'300'을 추출하기 위해서는 앞에 있는 'Right Margin: '을 우선 찾아야 하므로 "긍정형 후방탐색"을 사용합니다.
|
REGEXP_SUBSTR(description, '(?<=Right Margin\: )\d{1,3}')
|
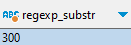
긍정이기 때문에 (?<=) 기호 안에 있는 정규표현식을 먼저 찾아냅니다.
그래서 "Right Margin\: "과 매칭되는 부분을 찾습니다.
그 이후에 이어지는 문자로 \d{1,3}에 대한 부분을 찾게되며 300이 매칭되므로 출력이 발생합니다.
-------------------------------------
2. 소수점이 포함된 실수 데이터를 가져오고 싶다.
소수에서 반드시 포함되는 값은 온점(.)입니다.
온점은 특수 문자이자 메타 문자이므로 백슬래시(\)와 함께 입력해야 메타 문자로 인식하지 않습니다.
샘플로 저장된 데이터를 다시 명시하겠습니다.
| Left Margin : 20cm; Right Margin: 300mm, bold=15pt, subtext : 10.5CM, largetext : 5.35cm |
위의 샘플에서 '10.5'와 '5.35'가 실수입니다.
이 정규표현식은 '300'이 나옵니다. 왜 그럴까요??
정규표현식에서 온점(.) 어떠한 문자 1개입니다. 따라서 \d로 정수 1개, 온점(.)으로 어떤 문자든 1개, \d{1}로 정수 1개.
그래서 정수만 3개 있는 '300'이 매칭됩니다.
이 정규표현식에서 '5.35'를 찾아서 출력하게 됩니다. 이건 온점(.)을 소수점으로 알아서 판단했기 때문일까요??
\d로 정수 1개, 온점(.)으로 어떤 문자든 1개, \d{2}로 무조건 정수 2개.
결국, 이 조합에서 있는 수는 5.35밖에 없기 때문에 출력이 그렇게 된 것입니다.
이번엔 온점(.) 앞에 백슬래시(\)를 붙여 '특수 문자인 온점(.)을 찾으라'고 명시했습니다.
어떤 수가 추출될까요? '0.5'가 출력됩니다. 어디서 나온 수일까요?
10.5에서 앞의 1이 잘린 결과입니다. 정규표현식은 작성된 규칙에 분명하게 반응하기 때문에 작성에 주의해야 합니다.
\d?도 결국 숫자 0~1개 매칭이므로 같은 결과가 나옵니다.
다음과 같은 정규표현식들이 전부 '10.5'를 출력합니다.
이는 문자열의 좌측(시작 부분)부터 가장 먼저 찾아낸 값을 반영하기 때문이며
만약 '5.35'가 가장 왼쪽에 있었다면 이 수가 먼저 정규표현식에 반응해 추출될 수 있습니다.
이번엔 소수점 부분인 "\.\d{2}"이 괄호에 담겨지고, 그 이후에 ?가 붙어있습니다. 무엇을 의미할까요?
이는 소수점 부분임을 의미하는 값이 없어도 되고(0), 1개 있어도 된다는 의미입니다.
단, \d+에 의해 정수 부분은 반드시 1개 이상이네요.
그래서 출력 결과로 '20'이 나옵니다.
20은 \d+에 의해 정수 1개 이상으로 구성되어 있으면서 (\.\d{2})?에 의해 소수점 부분은 없어도 무관하기 때문입니다.
- 끝 -